쿠버네티스에서 노드 헬스 체크(Node Health Check)는 클러스터의 안정적인 운영을 보장하는 메커니즘이다.
이 글에서는 두 가지 개념을 톺아본다.
- 노드 헬스 체크의 전반적인 구조와 개념
- 실제로 어떤 플로우와 시간 단위로 동작하는지
(공식 사이트에서 발췌한 내용을 기반으로 작성하였으나, 명확하지 않은 부분은 경험을 토대로 작성하였습니다. 이는 정확한 정보가 아닐 수 있음을 알려드립니다.)
공식 사이트
광고 클릭은 큰 힘이 됩니다!
Nodes
Kubernetes runs your workload by placing containers into Pods to run on Nodes. A node may be a virtual or physical machine, depending on the cluster. Each node is managed by the control plane and contains the services necessary to run Pods. Typically you h
kubernetes.io
Admission Control in Kubernetes
This page provides an overview of admission controllers. An admission controller is a piece of code that intercepts requests to the Kubernetes API server prior to persistence of the resource, but after the request is authenticated and authorized. Several i
kubernetes.io
kube-controller-manager
Synopsis The Kubernetes controller manager is a daemon that embeds the core control loops shipped with Kubernetes. In applications of robotics and automation, a control loop is a non-terminating loop that regulates the state of the system. In Kubernetes, a
kubernetes.io
kubelet
Synopsis The kubelet is the primary "node agent" that runs on each node. It can register the node with the apiserver using one of: the hostname; a flag to override the hostname; or specific logic for a cloud provider. The kubelet works in terms of a PodSpe
kubernetes.io
쿠버네티스 노드 헬스 체크
노드 헬스 체크는 “노드가 아직 살아 있는가?”를 주기적으로 확인하고, 살아 있지 않다고 판단되면 스케줄링, Taint, Eviction으로 대응하는 흐름이다.
컴포넌트
kubelet (노드 에이전트)
- 각 노드에서 실행된다.
- 자신의 노드 상태를 컨트롤 플레인에 하트비트(Heartbeat) 형태로 보고한다.
- Node 리소스의 .status를 업데이트하고, Lease 객체를 갱신한다.
kube-apiserver
- Node와 Lease 오브젝트를 저장하고 조회하는 API 엔드포인트 역할을 한다.
- kubelet과 컨트롤 플레인이 모두 여기로 요청을 보내며, 헬스 체크의 데이터 허브 역할을 한다.
node-lifecycle-controller (kube-controller-manager 내부)
- Node와 Lease 상태를 주기적으로 조회한다.
- 노드가 비정상이라고 판단되면 Ready 상태를 변경하고, Taint를 붙이며, 파드 퇴거를 트리거한다.
헬스 체크
kubelet은 자신의 생존 여부를 kube-node-lease 네임스페이스 lease 리소스를 갱신함과, 주기적인 Node.status 리소스 업데이트를 통해 알린다.
이후 node-lifecycle-controller(kube-controller-manger)가 일정 시간 동안 하트비트(Lease 갱신)를 받지 못하면 해당 노드를 비정상으로 간주한다. 이후 노드의Ready상태를Unknown또는False로 바꾸고, Taint를 부여하며, 파드를 퇴거한다.
노드 헬스 체크 플로우와 기본 시간 단위
kubelet이 보내는 하트비트(Lease 갱신)를 기준으로 노드의 상태성을 판단한다.
Lease 하트비트 업데이트 - (빈번한 업데이트)
쿠버네티스는 Lease 리소스를 사용해 노드 하트비트를 관리한다.
각 노드는 kube-node-lease 네임스페이스에 자신의 이름과 동일한 Lease 객체를 가진다.


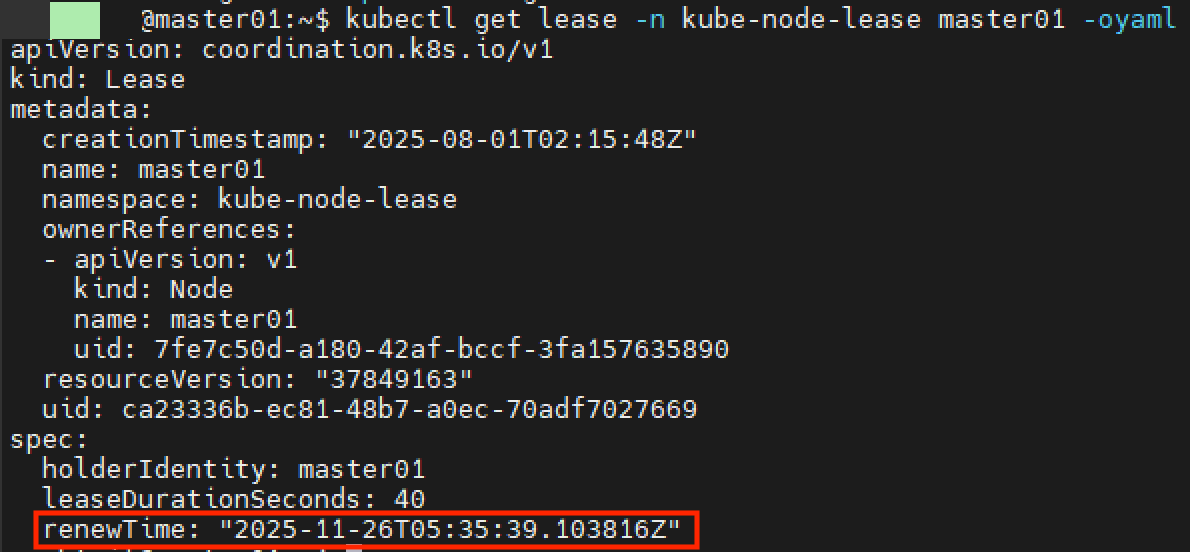
kubelet은 주기적으로 Lease 객체를 갱신하며 spec.renewTime 필드를 현재 시간으로 업데이트한다.
node-lifecycle-controller는 이 Lease의 spec.renewTime 갱신 시점을 보고 노드가 아직 살아 있는지 판단한다.
Node.status 업데이트 - (덜 빈번한 업데이트)
kubelet은 Node 리소스의 .status 또한 주기적으로 업데이트한다. (예: 용량, 할당량, 조건(Conditions) 등)
리소스 사용량이나 상태 변화가 있을 때, 또는 설정된 주기(node-status-update-frequency)를 기준으로 갱신한다.
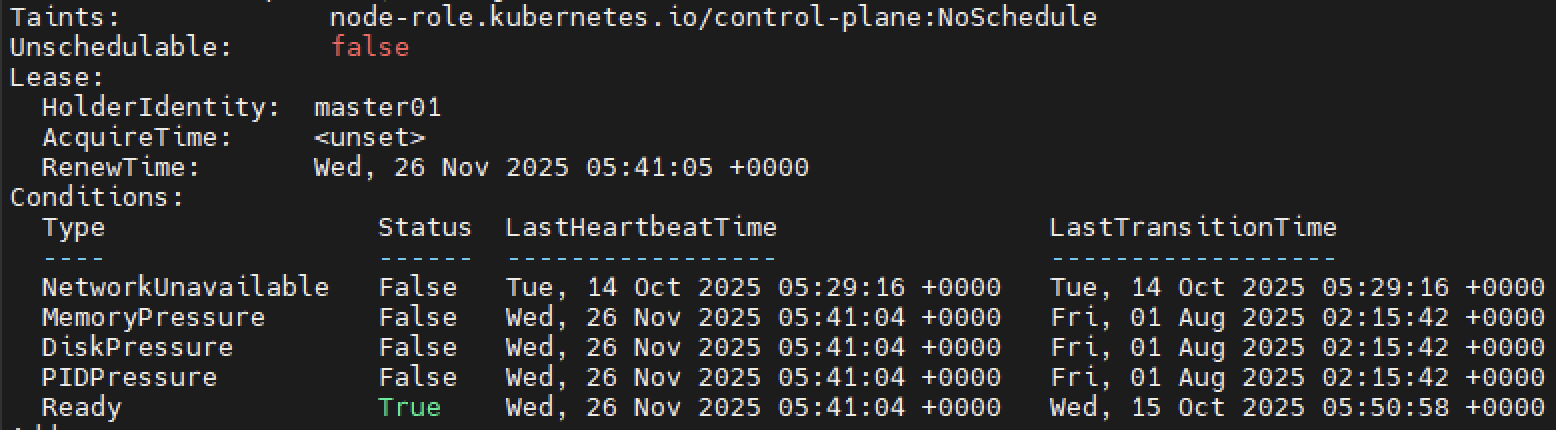
Lease 갱신이 주된 하트비트이고, Node.status는 비교적 덜 자주 업데이트되는 메타 정보에 가깝다. 또한 노드 정보 내 Lease 정보도 함께 포함된걸 볼 수 있다.
감지 및 상태 전이의 3단계
1단계 연결 끊김 감지
- 네트워크 단절 등으로 kubelet이 apiserver에 접속하지 못하면 Lease 갱신(하트비트)이 멈춘다.
- node-lifecycle-controller는 node-monitor-grace-period 동안 Lease 갱신이 없으면 노드를 비정상으로 본다.
- 이때 NodeCondition Ready 값은 True에서 Unknown으로 변경된다.
2단계 Taint 적용
- 노드 상태가 비정상으로 판단되면 컨트롤 플레인은 해당 노드에 Taint를 부여한다.
- node.kubernetes.io/unreachable (효과: NoSchedule, 필요 시 NoExecute도 추가)
- Ready가 Unknown 또는 False 상태로 지속되면 새로 생성되는 파드가 이 노드로 스케줄링되지 않게 막고(NoSchedule),
기존 파드를 퇴거시키기 위한 준비를 시작한다(NoExecute).
3단계 스케줄링 제한 및 파드 퇴거(Eviction)
- NoSchedule: 해당 Taint를 허용하는 Toleration이 없는 파드는 이 노드에 새로 스케줄링되지 않는다.
- NoExecute: Toleration이 없는 파드는 즉시 퇴거된다.
클러스터 노드의 대다수(기본 약 55% 이상) 가 동시에 비정상이 되면
→ 전체 클러스터 장애로 판단하고, 무분별한 파드 퇴거를 막기 위해 Eviction을 중단한다.
일부 노드만 비정상인 경우(Minority 장애)
→ 비정상 노드의 파드를 다른 정상 노드로 옮기기 위해 Eviction을 진행한다.
기본 시간 단위
노드 헬스 체크와 관련된 주요 시간 설정과 기본값은 다음과 같다 (Upstream Kubernetes/EKS 기본값 기준).
| kubelet | node-status-update-frequency | kubelet이 노드 상태(주로 Lease)를 얼마나 자주 갱신하는지에 대한 기본 주기 | 10 | 초 |
| node-lifecycle-controller | node-monitor-grace-period | 이 시간 동안 하트비트를 못 받으면 노드를 Unknown으로 간주 | 40 | 초 |
| kube-apiserver | default-unreachable-toleration-seconds | 연결 불가능(Unreachable) 노드에 대해 파드 퇴거를 시작하기 전까지 기다리는 유예 시간 | 300 | 초 (5분) |
※ 일부 문서·배포판에서는 node-monitor-grace-period를 50초로 표기하기도 한다.
실제 기본값은 쿠버네티스 버전·배포판(EKS, GKE 등)에 따라 다를 수 있으므로, 프로덕션 환경에서는 실제 플래그 값을 확인하는 것이 안전하다.
장애 시나리오
- 0초 시작:
노드 장애 발생 (전원 꺼짐, 네트워크 단절 등) kubelet이 더 이상 Lease를 갱신하지 못한다. - 0 ~ 40초 (node-monitor-grace-period) 경과:
컨트롤 플레인은 아직 기다리는 구간이다.
이 안에 노드가 복구되어 다시 Lease를 갱신하면 문제 없이 정상으로 유지한다. - 40초 이후:
node-lifecycle-controller는 노드가 Unhealthy라고 판단한다.
노드의 Ready Condition을 Unknown으로 바꾸고, node.kubernetes.io/unreachable Taint를 추가한다.
이 시점부터 새로운 파드는 해당 노드에 스케줄링되지 않는다. - 40초 + 300초 (default-unreachable-toleration-seconds) 경과:
약 5분 동안 노드가 여전히 복구되지 않으면, Toleration이 없는 파드부터 차례대로 Eviction이 진행되고, 스케줄러는 다른 정상 노드에 새 파드를 띄우기 시작한다. 단, 클러스터 다수 노드가 동시에 비정상이면 Eviction이 중단될 수 있다.
중요
잘못된 정보나, 문의등은 댓글로 메일과 함께 적어주시면 감사하겠습니다.
'Kubernetes' 카테고리의 다른 글
| I/O 병목과 ETCD 그리고 API 서버 (0) | 2025.12.09 |
|---|---|
| Ingress NGINX의 공식 은퇴 (0) | 2025.11.27 |
| Kubernetes Calico CNI와 스케줄링 실패 관계 (0) | 2025.11.06 |
| MinIO 공식 Docker 이미지 배포 중단 사태 (0) | 2025.10.29 |
| Kubernetes Internal Network 변경 절차 (0) | 2025.09.24 |